Hands, Memory, and a Job to Do
A code-dependent life form.
Part four of a series on agent harnesses. The earlier pieces covered the model-plus-harness idea, subagents, and sandboxes. This one is about the three things that turn a capable agent into one that earns its place in a real application.
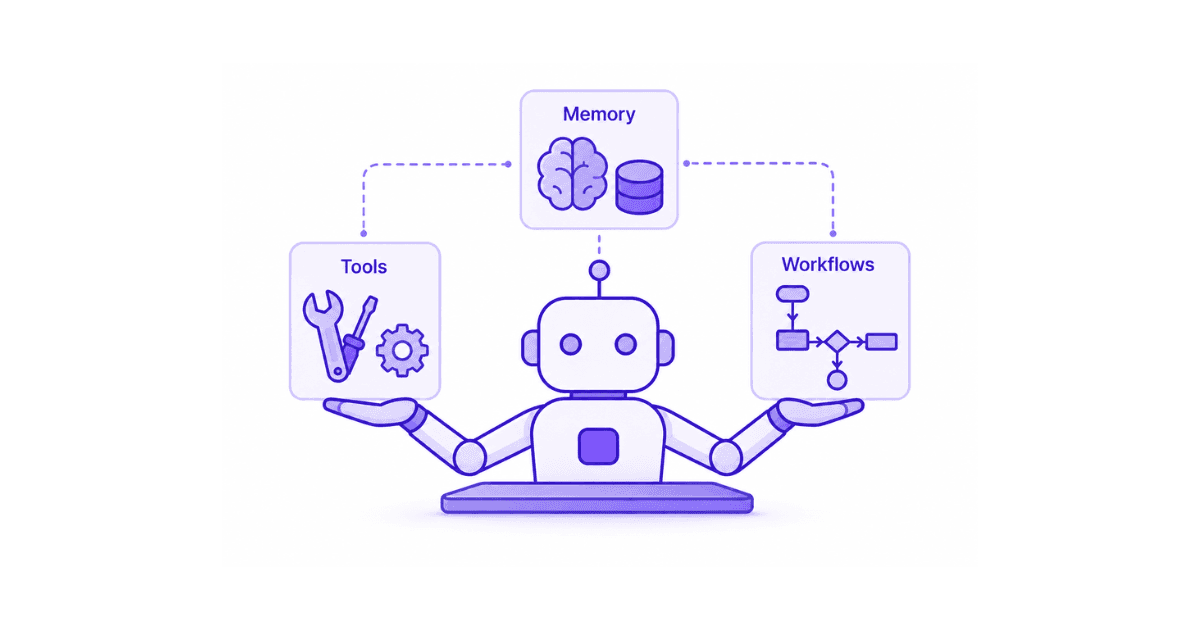
By now our agent can reason, delegate, and work safely inside a sandbox. That is a lot, but it is still a little sealed off from the world. A useful agent needs three more things: a way to reach into your systems, a way to remember what just happened, and a clean way to run a single job from start to finish. In Flue those are tools, memory, and workflows. We touched tools briefly in part one. Here we give all three the proper treatment.
Think of them as capability, continuity, and structure. Tools let the agent act on your data. Memory lets it carry context forward. Workflows wrap one finite unit of work so your application can run it like any other function.
Tools: reaching into your systems
A tool is a typed action you let the agent call while it works, such as looking up an order or creating a ticket. You define one with defineTool(...):
import { Type, defineTool } from '@flue/runtime';
export const lookupOrderStatus = defineTool({
name: 'lookup_order_status',
description: 'Look up the current fulfillment status for one order ID.',
parameters: Type.Object({
orderId: Type.String({ description: 'Order ID in the form order_1234' }),
}),
execute: async ({ orderId }) => {
const status = await orders.getStatus(String(orderId));
return status ?? 'No order was found.';
},
});
A tool has four parts: a name the model uses to call it, a description that helps it decide when the tool fits, a parameters schema for the inputs, and an execute function that does the work and returns text. Attach it to an agent through the tools list, and the model can call it whenever it needs the answer before responding.
The part that deserves real attention is access. The values the model puts into a tool's parameters are suggestions, not permission. A model choosing an orderId is fine. A model choosing which customer's orders it can see is not. So decide the boundary in your own code and let the model pick only within it:
export default createAgent(({ id: customerId }) => ({
model: 'anthropic/claude-haiku-4-5',
tools: [
defineTool({
name: 'lookup_customer_order',
description: 'Look up one order belonging to this customer.',
parameters: Type.Object({ orderId: Type.String() }),
execute: async ({ orderId }) => {
const status = await orders.getStatus(customerId, String(orderId));
return status ?? 'No accessible order was found.';
},
}),
],
}));
Here the model picks the order, but the customer is fixed by trusted application code. Never put credentials or tenant identifiers into model-selected arguments when your own code can supply them instead.
Memory: carrying context forward
A model forgets everything between calls. Continuity comes from the session, which is where an agent's work accumulates. Within one session, a later prompt builds on what came before:
const harness = await init(investigator);
const session = await harness.session();
await session.prompt(`Analyze this incident:\n\n${payload.incident}`);
const response = await session.prompt('Now recommend the next three actions.');
The second prompt never restates the incident, because the session already holds it. That is memory at work.

Notice the second call carries the earlier context with it. The harness is doing that bookkeeping so you do not have to. For longer-lived agents you can name sessions and persist them, so a conversation picks up later exactly where it left off. One clean rule to keep in mind: conversation history belongs in the session store, while durable application data belongs in your own data layer. Do not blur the two.
Workflows: wrapping a single job
Sometimes you do not want an ongoing conversation at all. You want to run one finite job, get a result, and be done: summarize a document, review a change, triage a ticket. That is a workflow. In Flue it is a file in src/workflows/ that exports a run(...) function, and the filename becomes its name:
import { createAgent, type FlueContext } from '@flue/runtime';
const summarizer = createAgent(() => ({
model: 'anthropic/claude-haiku-4-5',
instructions: 'Summarize the supplied document clearly and concisely.',
}));
export async function run({ init, payload }: FlueContext<{ text: string }>) {
const harness = await init(summarizer);
const session = await harness.session();
const response = await session.prompt(payload.text);
return { summary: response.text };
}
The difference from a continuing agent is the shape of the work, not the parts inside it.

A workflow runs once and returns. An agent keeps accepting messages over time. Use a workflow for background jobs, document transforms, and CI tasks, and an agent when someone is holding a conversation.
Because a workflow is just code, you can do ordinary TypeScript work around the agent: load data, branch on input, transform the output. And when later code depends on specific fields, ask for a structured result instead of prose:
const response = await session.prompt(payload.ticket, {
result: v.object({
priority: v.picklist(['low', 'medium', 'high']),
summary: v.string(),
}),
});
return response.data;
Now the agent must return data that fits the schema before your workflow ever sees it, so you get a dependable priority and summary rather than a paragraph to parse.
Optimizing all three
A few habits make these pay off together.
Give tools sharp names and descriptions. The model decides when to call a tool from its name and description alone.
lookup_order_statusinvites the right call. A vague name invites the wrong one.Keep sessions lean. A session that accumulates forever gets slow and expensive. Start a fresh session for unrelated work rather than letting one conversation collect everything.
Match the model to the job. A summarizer can run on a fast, cheap model while a harder reasoning workflow uses a stronger one. Each agent and workflow sets its own model, so you pay for capability only where it is needed.
Prefer structured results when code consumes the output. Parsing prose is fragile. A result schema turns the agent's answer into data you can trust.
Best practices
A short checklist across the three:
Treat tool inputs as untrusted. Model-selected arguments are not an authorization boundary. Fix the sensitive values in your own code and let the model choose only within that scope.
Separate conversation from application data. Session history lives in the session store. Anything durable your business depends on lives in your own database, not in the conversation.
Pick the right shape for the work. Reach for a workflow when the job is finite and a result is all you need. Reach for an agent when the interaction continues over time.
Return data, not prose, at boundaries. Whenever a workflow's output feeds other code, define a result schema so the contract is explicit and validated.
Prefer a narrow tool over a broad shell. If a defined tool can perform an action safely, use it instead of leaning on open-ended sandbox commands for the same job.
Where to go next
Try wiring all three together in one small workflow: give an agent a tool, let a second prompt build on the first through the session, and return a structured result. Once that clicks, you have the full working vocabulary of an agent that does real work in a real application. The Flue guides on tools, agents, and workflows go deeper on each.
If you ever need help or just want to chat, DM me on Twitter / X or LinkedIn.