One Agent Is Not Always Enough
A code-dependent life form.
Part two of a series on agent harnesses. If you have not read part one, it introduces the idea that an agent is a model plus the harness around it. This piece builds on that, so a quick skim first will help.
In the first article we built a single agent: one model, one set of instructions, a tool or two, running in a loop until the task was done. That works beautifully right up until the task gets big. A support agent that also has to classify the issue, check policy, and draft a reply is now juggling four jobs in one conversation. The context gets crowded, the instructions get long, and the model starts to lose the thread.
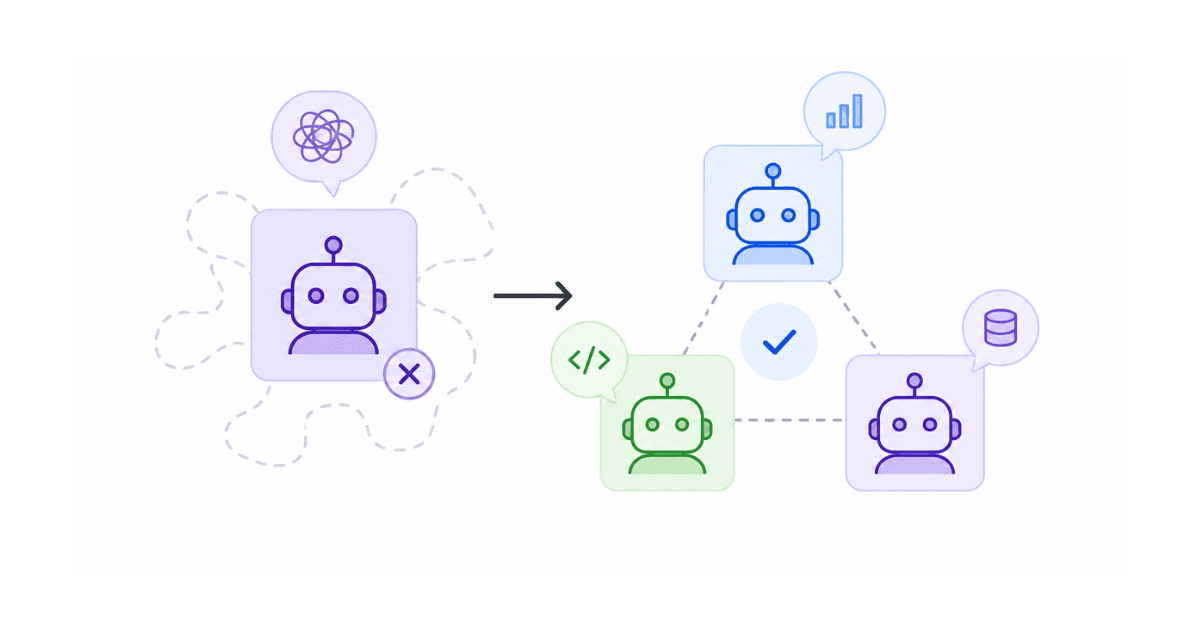
The fix is not a bigger prompt. It is a second agent. When one agent hands a focused piece of work to a specialist and then keeps going with the answer, that specialist is a subagent. This article shows what subagents are, why they help, and how to build them in Flue.
Why split the work
A single agent holding everything has three problems that get worse as it grows:
Crowded context. Every instruction, tool, and past message shares the same window. The more an agent is asked to do, the more noise sits between the model and the thing it actually needs right now.
Mixed responsibilities. Instructions written for classifying an issue pull in a different direction than instructions for writing a friendly reply. Cram both into one agent and each gets a little worse.
No reuse. If three different agents all need to review code for risks, you end up writing that reviewer logic three times.
Subagents solve all three by giving a job its own small, clean agent that can be called when needed and reused wherever it fits.
How delegation works in Flue
A subagent in Flue is an agent profile: a named specialist declared on a parent agent. The important detail is what happens when the parent delegates. The work does not continue in the parent's conversation. It runs in a separate child session with its own context, and only the result comes back.

That clean separation is the whole point. The subagent does not inherit a long transcript it does not need. It gets the request, does its one job with its own instructions, and returns a focused answer. The parent stays in charge of the conversation the entire time.
Defining your first subagent
You create a specialist with defineAgentProfile(...) and then list it in the parent agent's subagents configuration. Here is a support assistant that can hand off classification to a dedicated classifier:
import { createAgent, defineAgentProfile } from '@flue/runtime';
const issueClassifier = defineAgentProfile({
name: 'issue_classifier',
description: 'Classifies support issues for routing.',
instructions: 'Return the likely product area and urgency for the reported issue.',
});
export default createAgent(() => ({
model: 'anthropic/claude-sonnet-4-6',
instructions: 'Help resolve support requests. Delegate classification when it helps your answer.',
subagents: [issueClassifier],
}));
Two things are worth noticing. The classifier has its own short, sharp instructions that say nothing about writing replies, because that is not its job. And the parent's instructions simply tell it that delegation is available and when to reach for it. The model decides the rest.
One detail that trips people up: a subagent is not a separate endpoint you can call from outside. There is no /agents/issue_classifier/:id. It exists only as a specialist the parent can delegate to. If you need a standalone addressable agent, that is a regular agent, not a subagent.
Letting the agent decide
Once a parent has subagents configured, Flue gives it a built-in task capability. The parent can choose, on its own, to start a child session for a subagent and use the answer that comes back.

In this flow the parent never showed the user the classification step. It delegated quietly, got back a tidy result, and folded it into the answer. From the user's side it looks like one smooth response, which is exactly what you want.
Choosing delegation yourself in a workflow
Sometimes you do not want to leave the decision to the model. When your application logic knows a specific specialist must run, a workflow can call session.task(...) directly with the subagent's name. You can also ask for a validated, typed result instead of free text:
import { createAgent, defineAgentProfile, type FlueContext } from '@flue/runtime';
import * as v from 'valibot';
const reviewer = defineAgentProfile({
name: 'reviewer',
instructions: 'Review the proposed change and identify concrete correctness risks.',
});
const coordinator = createAgent(() => ({
model: 'anthropic/claude-sonnet-4-6',
subagents: [reviewer],
}));
const Review = v.object({
summary: v.string(),
risks: v.array(v.string()),
});
export async function run({ init, payload }: FlueContext<{ change: string }>) {
const harness = await init(coordinator);
const session = await harness.session();
const response = await session.task(payload.change, {
agent: 'reviewer',
result: Review,
});
return response.data;
}
Here the workflow picks reviewer rather than hoping the model chooses to. The result schema means the answer comes back as structured data you can trust, with a summary string and a risks array, instead of a paragraph you have to parse. This is the pattern to reach for when delegation is part of your application's logic, not the agent's judgment.
Optimizing with subagents
Subagents are themselves an optimization technique, but a few habits make them pay off more.
Keep each specialist narrow. A subagent that does one thing well stays cheap and predictable. If a profile's instructions start growing several jobs, that is the signal to split it again.
Match the model to the specialist. A parent doing hard reasoning might run on a strong model, while a simple classifier runs on a fast, cheap one. Because each profile sets its own model, you only pay for capability where it is actually needed.
Reuse profiles across agents. A
reviewerorclassifierprofile can be declared on several different parents. Define it once and share it, rather than rebuilding the same specialist in each agent.Let parallel work stay parallel. Independent subtasks that do not depend on each other can be delegated without bloating one giant conversation. Each child session carries only what it needs.
Best practices
A short checklist for keeping a multi-agent setup clean:
Give every profile a clear name and description. The parent uses these to decide when delegation fits, so vague descriptions lead to vague delegation. Use plain, specific language like
issue_classifierorreviewer.Do not leak the parent's transcript into specialists. This is already how Flue works, and it is worth protecting. A subagent should receive only the request it needs, not the whole history.
Ask for typed results when the answer feeds your code. When a workflow consumes a subagent's output, define a result schema so you get structured, validated data instead of prose.
Remember the shared sandbox. When a subagent runs inside a configured sandbox, it uses the same boundary as its parent. Scope that boundary with the work in mind so delegated tasks cannot reach further than intended.
Decide who chooses. Let the model delegate when the choice depends on the request, and call
session.task(...)directly when your application already knows which specialist must run.
Where to go next
The fastest way to feel the difference is to take a single agent that is doing too much and split off one job. Pull the noisiest responsibility into a profile, declare it as a subagent, and watch the parent's instructions shrink. Once one handoff works, adding a second specialist is the same move again. The Flue subagents guide covers the full API when you are ready to go deeper, and the next article in this series will look at giving these agents a safe place to run real work
If you ever need help or just want to chat, DM me on Twitter / X or LinkedIn.